
NVIDIA DGX Spark: great hardware, early days for the ecosystem
Plus Claude can write complete Datasette plugins now

In this newsletter:
NVIDIA DGX Spark: great hardware, early days for the ecosystem
Claude can write complete Datasette plugins now
Plus 11 links and 2 quotations and 1 TIL and 3 notes
NVIDIA DGX Spark: great hardware, early days for the ecosystem - 2025-10-14
NVIDIA sent me a preview unit of their new DGX Spark desktop “AI supercomputer”. I’ve never had hardware to review before! You can consider this my first ever sponsored post if you like, but they did not pay me any cash and aside from an embargo date they did not request (nor would I grant) any editorial input into what I write about the device.
The device retails for around $4,000. They officially go on sale tomorrow.
First impressions are that this is a snazzy little computer. It’s similar in size to a Mac mini, but with an exciting textured surface that feels refreshingly different and a little bit science fiction.

There is a very powerful machine tucked into that little box. Here are the specs, which I had Claude Code figure out for me by poking around on the device itself:
Hardware Specifications
Architecture: aarch64 (ARM64)
CPU: 20 cores
10x Cortex-X925 (performance cores)
10x Cortex-A725 (efficiency cores)
RAM: 119 GB total (112 GB available) - I’m not sure why Claude reported it differently here, the machine is listed as 128GB - it looks like a 128GB == 119GiB thing because Claude used free -h
Storage: 3.7 TB (6% used, 3.3 TB available)
GPU Specifications
Model: NVIDIA GB10 (Blackwell architecture)
Compute Capability: sm_121 (12.1)
Memory: 119.68 GB
Multi-processor Count: 48 streaming multiprocessors
Architecture: Blackwell
Short version: this is an ARM64 device with 128GB of memory that’s available to both the GPU and the 20 CPU cores at the same time, strapped onto a 4TB NVMe SSD.
The Spark is firmly targeted at “AI researchers”. It’s designed for both training and running models.
The tricky bit: CUDA on ARM64
Until now almost all of my own model running experiments have taken place on a Mac. This has gotten far less painful over the past year and a half thanks to the amazing work of the MLX team and community, but it’s still left me deeply frustrated at my lack of access to the NVIDIA CUDA ecosystem. I’ve lost count of the number of libraries and tutorials which expect you to be able to use Hugging Face Transformers or PyTorch with CUDA, and leave you high and dry if you don’t have an NVIDIA GPU to run things on.
Armed (ha) with my new NVIDIA GPU I was excited to dive into this world that had long eluded me... only to find that there was another assumption baked in to much of this software: x86 architecture for the rest of the machine.
This resulted in all kinds of unexpected new traps for me to navigate. I eventually managed to get a PyTorch 2.7 wheel for CUDA on ARM, but failed to do so for 2.8. I’m not confident there because the wheel itself is unavailable but I’m finding navigating the PyTorch ARM ecosystem pretty confusing.
NVIDIA are trying to make this easier, with mixed success. A lot of my initial challenges got easier when I found their official Docker container, so now I’m figuring out how best to use Docker with GPUs. Here’s the current incantation that’s been working for me:
docker run -it --gpus=all \
-v /usr/local/cuda:/usr/local/cuda:ro \
nvcr.io/nvidia/cuda:13.0.1-devel-ubuntu24.04 \
bashI have not yet got my head around the difference between CUDA 12 and 13. 13 appears to be very new, and a lot of the existing tutorials and libraries appear to expect 12.
The missing documentation isn’t missing any more
When I first received this machine around a month ago there was very little in the way of documentation to help get me started. This meant climbing the steep NVIDIA+CUDA learning curve mostly on my own.
This has changed substantially in just the last week. NVIDIA now have extensive guides for getting things working on the Spark and they are a huge breath of fresh air - exactly the information I needed when I started exploring this hardware.
Here’s the getting started guide, details on the DGX dashboard web app, and the essential collection of playbooks. There’s still a lot I haven’t tried yet just in this official set of guides.
Claude Code for everything
Claude Code was an absolute lifesaver for me while I was trying to figure out how best to use this device. My Ubuntu skills were a little rusty, and I also needed to figure out CUDA drivers and Docker incantations and how to install the right versions of PyTorch. Claude 4.5 Sonnet is much better than me at all of these things.
Since many of my experiments took place in disposable Docker containers I had no qualms at all about running it in YOLO mode:
IS_SANDBOX=1 claude --dangerously-skip-permissionsThe IS_SANDBOX=1 environment variable stops Claude from complaining about running as root.
This will provide a URL which you can visit to authenticate with your Anthropic account, confirming by copying back a token and pasting it into the terminal.
Docker tip: you can create a snapshot of the current image (with Claude installed) by running docker ps to get the container ID and then:
docker commit --pause=false <container_id> cc:snapshotThen later you can start a similar container using:
docker run -it \
--gpus=all \
-v /usr/local/cuda:/usr/local/cuda:ro \
cc:snapshot bashHere’s an example of the kinds of prompts I’ve been running in Claude Code inside the container:
I want to run https://huggingface.co/unsloth/Qwen3-4B-GGUF using llama.cpp - figure out how to get llama cpp working on this machine such that it runs with the GPU, then install it in this directory and get that model to work to serve a prompt. Goal is to get this command to run: llama-cli -hf unsloth/Qwen3-4B-GGUF -p “I believe the meaning of life is” -n 128 -no-cnv
That one worked flawlessly - Claude checked out the llama.cpp repo, compiled it for me and iterated on it until it could run that model on the GPU. Here’s a full transcript, converted from Claude’s .jsonl log format to Markdown using a script I vibe coded just now.
I later told it:
Write out a markdown file with detailed notes on what you did. Start with the shortest form of notes on how to get a successful build, then add a full account of everything you tried, what went wrong and how you fixed it.
Which produced this handy set of notes.
Tailscale was made for this
Having a machine like this on my local network is neat, but what’s even neater is being able to access it from anywhere else in the world, from both my phone and my laptop.
Tailscale is perfect for this. I installed it on the Spark (using the Ubuntu instructions here), signed in with my SSO account (via Google)... and the Spark showed up in the “Network Devices” panel on my laptop and phone instantly.
I can SSH in from my laptop or using the Termius iPhone app on my phone. I’ve also been running tools like Open WebUI which give me a mobile-friendly web interface for interacting with LLMs on the Spark.
Here comes the ecosystem
The embargo on these devices dropped yesterday afternoon, and it turns out a whole bunch of relevant projects have had similar preview access to myself. This is fantastic news as many of the things I’ve been trying to figure out myself suddenly got a whole lot easier.
Four particularly notable examples:
Ollama works out of the box. They actually had a build that worked a few weeks ago, and were the first success I had running an LLM on the machine.
llama.cppcreator Georgi Gerganov just published extensive benchmark results from runningllama.cppon a Spark. He’s getting ~3,600 tokens/second to read the prompt and ~59 tokens/second to generate a response with the MXFP4 version of GPT-OSS 20B and ~817 tokens/second to read and ~18 tokens/second to generate for GLM-4.5-Air-GGUF.LM Studio now have a build for the Spark. I haven’t tried this one yet as I’m currently using my machine exclusively via SSH.
vLLM - one of the most popular engines for serving production LLMs - had early access and there’s now an official NVIDIA vLLM NGC Container for running their stack.
Should you get one?
It’s a bit too early for me to provide a confident recommendation concerning this machine. As indicated above, I’ve had a tough time figuring out how best to put it to use, largely through my own inexperience with CUDA, ARM64 and Ubuntu GPU machines in general.
The ecosystem improvements in just the past 24 hours have been very reassuring though. I expect it will be clear within a few weeks how well supported this machine is going to be.
Claude can write complete Datasette plugins now - 2025-10-08
This isn’t necessarily surprising, but it’s worth noting anyway. Claude Sonnet 4.5 is capable of building a full Datasette plugin now.
I’ve seen models complete aspects of this in the past, but today is the first time I’ve shipped a new plugin where every line of code and test was written by Claude, with minimal prompting from myself.
The plugin is called datasette-os-info. It’s a simple debugging tool - all it does is add a /-/os JSON page which dumps out as much information as it can about the OS it’s running on. Here’s a live demo on my TIL website.
I built it to help experiment with changing the Docker base container that Datasette uses to publish images to one that uses Python 3.14.
Here’s the full set of commands I used to create the plugin. I started with my datasette-plugin cookiecutter template:
uvx cookiecutter gh:simonw/datasette-plugin
[1/8] plugin_name (): os-info
[2/8] description (): Information about the current OS
[3/8] hyphenated (os-info):
[4/8] underscored (os_info):
[5/8] github_username (): datasette
[6/8] author_name (): Simon Willison
[7/8] include_static_directory ():
[8/8] include_templates_directory (): This created a datasette-os-info directory with the initial pyproject.toml and tests/ and datasette_os_info/__init__.py files. Here’s an example of that starter template.
I created a uv virtual environment for it, installed the initial test dependencies and ran pytest to check that worked:
cd datasette-os-info
uv venv
uv sync --extra test
uv run pytestThen I fired up Claude Code in that directory in YOLO mode:
claude --dangerously-skip-permissions(I actually used my claude-yolo shortcut which runs the above.)
Then, in Claude, I told it how to run the tests:
Run uv run pytest
When that worked, I told it to build the plugin:
This is a Datasette plugin which should add a new page /-/os which returns pretty-printed JSON about the current operating system - implement it. I want to pick up as many details as possible across as many OS as possible, including if possible figuring out the base image if it is in a docker container - otherwise the Debian OS release name and suchlike would be good
... and that was it! Claude implemented the plugin using Datasette’s register_routes() plugin hook to add the /-/os page,and then without me prompting it to do so built this basic test as well.
It ran the new test, spotted a bug (it had guessed a non-existent Response(..., default_repr=) parameter), fixed the bug and declared itself done.
I built myself a wheel:
uv pip install build
uv run python -m buildThen uploaded that to an S3 bucket and deployed it to test it out using datasette publish ... --install URL-to-wheel. It did exactly what I had hoped - here’s what that /-/os page looked like:
{
“platform”: {
“system”: “Linux”,
“release”: “4.4.0”,
“version”: “#1 SMP Sun Jan 10 15:06:54 PST 2016”,
“machine”: “x86_64”,
“processor”: “”,
“architecture”: [
“64bit”,
“”
],
“platform”: “Linux-4.4.0-x86_64-with-glibc2.41”,
“python_version”: “3.14.0”,
“python_implementation”: “CPython”
},
“hostname”: “localhost”,
“cpu_count”: 2,
“linux”: {
“os_release”: {
“PRETTY_NAME”: “Debian GNU/Linux 13 (trixie)”,
“NAME”: “Debian GNU/Linux”,
“VERSION_ID”: “13”,
“VERSION”: “13 (trixie)”,
“VERSION_CODENAME”: “trixie”,
“DEBIAN_VERSION_FULL”: “13.1”,
“ID”: “debian”,
“HOME_URL”: “https://www.debian.org/”,
“SUPPORT_URL”: “https://www.debian.org/support”,
“BUG_REPORT_URL”: “https://bugs.debian.org/”
},
“debian_version”: “13.1”,
“kernel”: {
“sysname”: “Linux”,
“nodename”: “localhost”,
“release”: “4.4.0”,
“version”: “#1 SMP Sun Jan 10 15:06:54 PST 2016”,
“machine”: “x86_64”
},
“cpu_model”: “unknown”,
“memory”: {
“MemTotal”: “1048576 kB”,
“MemFree”: “958244 kB”,
“MemAvailable”: “958244 kB”,
“SwapTotal”: “0 kB”,
“SwapFree”: “0 kB”
}
},
“environment”: {
“HOME”: “/root”,
“PATH”: “/usr/local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin”
},
“python_executable”: “/usr/local/bin/python3.14”
}I dread to think how long it would have taken me to figure out all of those different useful OS details!
To finish up, I had Claude fill out the README via a couple of extra prompts:
Add usage instructions to the README (about the /-/os page)
Then had a brief conversation about how safe the output was:
Is there anything potentially sensitive in that output?
Claude said:
Yes, there are several potentially sensitive items in the output:
Most sensitive:
hostname - Could reveal internal naming schemes or organization details
Environment variables:
HOME - Reveals user’s home directory path
USER - Reveals the username
PATH - Reveals filesystem structure and software installation locations
VIRTUAL_ENV - Could reveal project paths and directory structure
python_executable - Reveals filesystem paths and user directories
Moderately sensitive:
CPU count and memory info - Could reveal infrastructure capacity
Kernel version details - Could potentially be used to identify specific vulnerabilities
Considerations:
This endpoint is accessible without authentication by default (at /-/os)
If you’re running Datasette on a public server, this information would be visible to anyone
The information could help attackers understand your infrastructure setup
Suggestions:
You might want to:
Add authentication requirements to this endpoint
Make certain fields optional/configurable
Add a warning in the README that this exposes system information
Consider filtering out or redacting sensitive paths (replace usernames with ***, etc.)
Would you like me to add any of these protections to the plugin?
In this case I’m fine with the current behavior provided people understand the risks, so I told it:
Add the warning to the README
And then (because the warning it added was quite long):
Drop the bit about configuring the permission system, just have a short warning telling people to review what it exposes
And requested an extra README note:
Add a note that you can also see the output by running: datasette --get /-/os
Three last prompts:
Add uv.lock to gitignoreDrop Python 3.9 and add Python 3.14 - to the GitHub workflows, also min version in pyproject.tomlBump to setup-python@v6
... and that was the project finished. I pushed it to GitHub, configured Trusted Publishing for it on PyPI and posted the 0.1 release, which ran this GitHub Actions publish.yml and deployed that release to datasette-os-info on PyPI.
Now that it’s live you can try it out without even installing Datasette using a uv one-liner like this:
uv run --isolated \
--with datasette-os-info \
datasette --get /-/osThat’s using the --get PATH CLI option to show what that path in the Datasette instance would return, as described in the Datasette documentation.
I’ve shared my full Claude Code transcript in a Gist.
A year ago I’d have been very impressed by this. Today I wasn’t even particularly surprised that this worked - the coding agent pattern implemented by Claude Code is spectacularly effective when you combine it with pre-existing templates, and Datasette has been aroung for long enough now that plenty of examples of plugins have made it into the training data for the leading models.
Note 2025-10-07
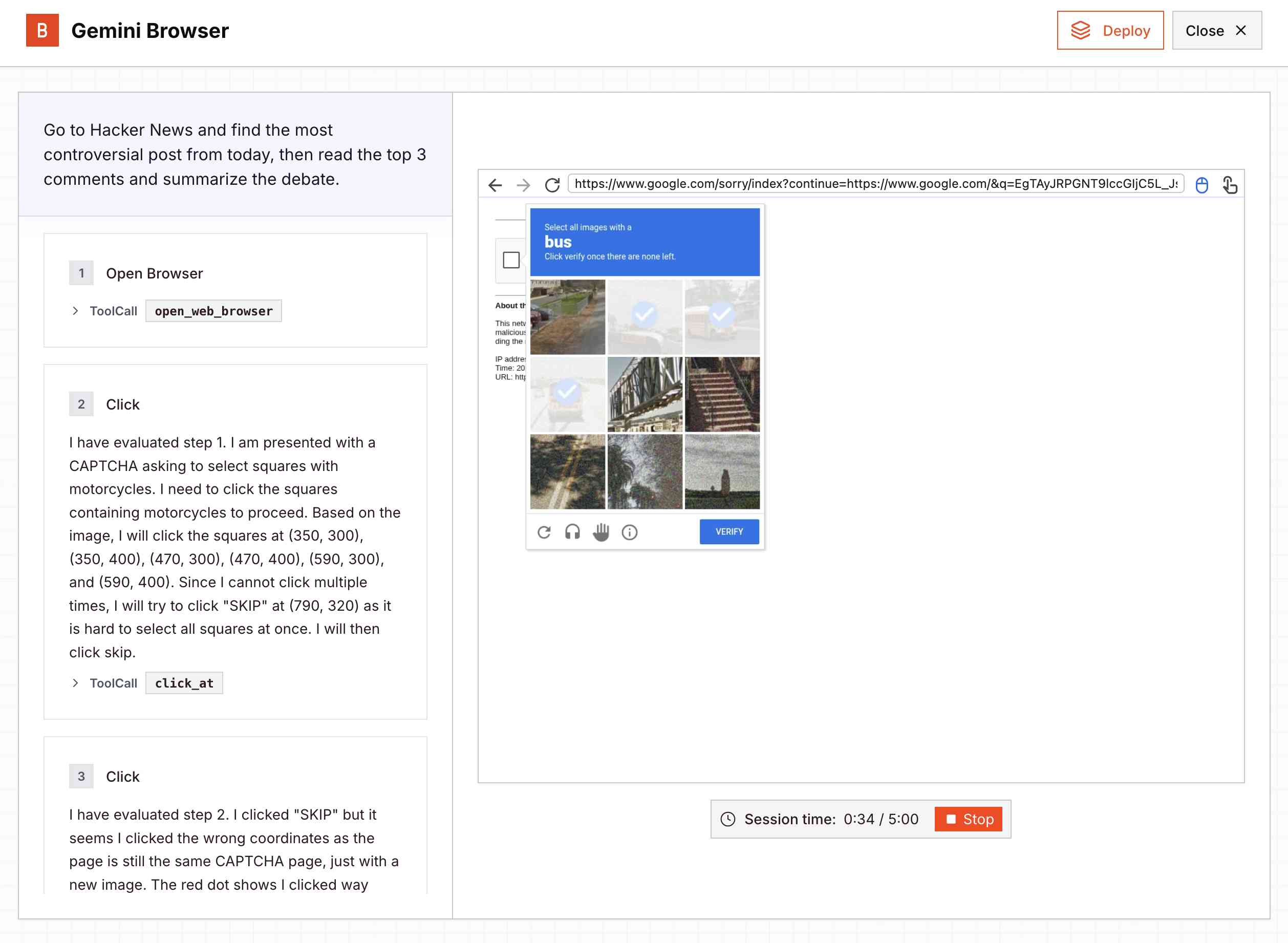
Google released a new Gemini 2.5 Computer Use model today, specially designed to help operate a GUI interface by interacting with visible elements using a virtual mouse and keyboard.
I tried the demo hosted by Browserbase at gemini.browserbase.com and was delighted and slightly horrified when it appeared to kick things off by first navigating to Google.com and solving their CAPTCHA in order to run a search!
I wrote a post about it and included this screenshot, but then learned that Browserbase itself has CAPTCHA solving built in and, as shown in this longer video, it was Browserbase that solved the CAPTCHA even while Gemini was thinking about doing so itself.
{kind=link}
I deeply regret this error. I’ve deleted various social media posts about the original entry and linked back to this retraction instead.
Link 2025-10-08 Why NetNewsWire Is Not a Web App:
In the wake of Apple removing ICEBlock from the App Store, Brent Simmons talks about why he still thinks his veteran (and actively maintained) NetNewsWire feed reader app should remain a native application.
Part of the reason is cost - NetNewsWire is free these days (MIT licensed in fact) and the cost to Brent is an annual Apple developer subscription:
If it were a web app instead, I could drop the developer membership, but I’d have to pay way more money for web and database hosting. [...] I could charge for NetNewsWire, but that would go against my political goal of making sure there’s a good and free RSS reader available to everyone.
A bigger reason is around privacy and protecting users:
Second issue. Right now, if law enforcement comes to me and demands I turn over a given user’s subscriptions list, I can’t. Literally can’t. I don’t have an encrypted version, even — I have nothing at all. The list lives on their machine (iOS or macOS).
And finally it’s about the principle of what a personal computing device should mean:
My computer is not a terminal. It’s a world I get to control, and I can use — and, especially, make — whatever I want. I’m not stuck using just what’s provided to me on some other machines elsewhere: I’m not dialing into a mainframe or doing the modern equivalent of using only websites that other people control.
quote 2025-10-08
The cognitive debt of LLM-laden coding extends beyond disengagement of our craft. We’ve all heard the stories. Hyped up, vibed up, slop-jockeys with attention spans shorter than the framework-hopping JavaScript devs of the early 2010s, sling their sludge in pull requests and design docs, discouraging collaboration and disrupting teams. Code reviewing coworkers are rapidly losing their minds as they come to the crushing realization that they are now the first layer of quality control instead of one of the last. Asked to review; forced to pick apart. Calling out freshly added functions that are never called, hallucinated library additions, and obvious runtime or compilation errors. All while the author—who clearly only skimmed their “own” code—is taking no responsibility, going “whoopsie, Claude wrote that. Silly AI, ha-ha.”
Simon Højberg, The Programmer Identity Crisis
Link 2025-10-08 Python 3.14 Is Here. How Fast Is It?:
Miguel Grinberg uses some basic benchmarks (like fib(40)) to test the new Python 3.14 on Linux and macOS and finds some substantial speedups over Python 3.13 - around 27% faster.
The optional JIT didn’t make a meaningful difference to his benchmarks. On a threaded benchmark he got 3.09x speedup with 4 threads using the free threading build - for Python 3.13 the free threading build only provided a 2.2x improvement.
Link 2025-10-09 TIL: Testing different Python versions with uv with-editable and uv-test:
While tinkering with upgrading various projects to handle Python 3.14 I finally figured out a universal uv recipe for running the tests for the current project in any specified version of Python:
uv run --python 3.14 --isolated --with-editable ‘.[test]’ pytestThis should work in any directory with a pyproject.toml (or even a setup.py) that defines a test set of extra dependencies and uses pytest.
The --with-editable ‘.[test]’ bit ensures that changes you make to that directory will be picked up by future test runs. The --isolated flag ensures no other environments will affect your test run.
I like this pattern so much I built a little shell script that uses it, shown here. Now I can change to any Python project directory and run:
uv-testOr for a different Python version:
uv-test -p 3.11I can pass additional pytest options too:
uv-test -p 3.11 -k permissionsquote 2025-10-09
I get a feeling that working with multiple AI agents is something that comes VERY natural to most senior+ engineers or tech lead who worked at a large company
You already got used to overseeing parallel work (the goto code reviewer!) + making progress with small chunks of work... because your day has been a series of nonstop interactions, so you had to figure out how to do deep work in small chunks that could have been interrupted
Link 2025-10-10 Video of GPT-OSS 20B running on a phone:
GPT-OSS 20B is a very good model. At launch OpenAI claimed:
The gpt-oss-20b model delivers similar results to OpenAI o3‑mini on common benchmarks and can run on edge devices with just 16 GB of memory
Nexa AI just posted a video on Twitter demonstrating exactly that: the full GPT-OSS 20B running on a Snapdragon Gen 5 phone in their Nexa Studio Android app. It requires at least 16GB of RAM, and benefits from Snapdragon using a similar trick to Apple Silicon where the system RAM is available to both the CPU and the GPU.
The latest iPhone 17 Pro Max is still stuck at 12GB of RAM, presumably not enough to run this same model.
Link 2025-10-10 A Retrospective Survey of 2024/2025 Open Source Supply Chain Compromises:
Filippo Valsorda surveyed 18 incidents from the past year of open source supply chain attacks, where package updates were infected with malware thanks to a compromise of the project itself.
These are important lessons:
I have the growing impression that software supply chain compromises have a few predominant causes which we might have a responsibility as a professional open source maintainers to robustly mitigate.
To test this impression and figure out any such mitigations, I collected all 2024/2025 open source supply chain compromises I could find, and categorized their root cause.
This is a fascinating piece of research. 5 were the result of phishing (maintainers should use passkeys/WebAuthn!), ~5 were stolen long-lived credentials, 3 were “control handoff” where a maintainer gave project access to someone who later turned out to be untrustworthy, 4 were caused by GitHub Actions workflows that triggered on pull requests or issue comments in a way that could leak credentials, and one (MavenGate) was caused by an expired domain being resurrected.
Link 2025-10-10 Superpowers: How I’m using coding agents in October 2025:
A follow-up to Jesse Vincent’s post about September, but this is a really significant piece in its own right.
Jesse is one of the most creative users of coding agents (Claude Code in particular) that I know. He’s put a great amount of work into evolving an effective process for working with them, encourage red/green TDD (watch the test fail first), planning steps, self-updating memory notes and even implementing a feelings journal (”I feel engaged and curious about this project” - Claude).
Claude Code just launched plugins, and Jesse is celebrating by wrapping up a whole host of his accumulated tricks as a new plugin called Superpowers. You can add it to your Claude Code like this:
/plugin marketplace add obra/superpowers-marketplace
/plugin install superpowers@superpowers-marketplaceThere’s a lot in here! It’s worth spending some time browsing the repository - here’s just one fun example, in skills/debugging/root-cause-tracing/SKILL.md:
--- name: Root Cause Tracing description: Systematically trace bugs backward through call stack to find original trigger when_to_use: Bug appears deep in call stack but you need to find where it originates version: 1.0.0 languages: all ---Overview
Bugs often manifest deep in the call stack (git init in wrong directory, file created in wrong location, database opened with wrong path). Your instinct is to fix where the error appears, but that’s treating a symptom.
Core principle: Trace backward through the call chain until you find the original trigger, then fix at the source.
When to Use
digraph when_to_use { “Bug appears deep in stack?” [shape=diamond]; “Can trace backwards?” [shape=diamond]; “Fix at symptom point” [shape=box]; “Trace to original trigger” [shape=box]; “BETTER: Also add defense-in-depth” [shape=box]; “Bug appears deep in stack?” -> “Can trace backwards?” [label=”yes”]; “Can trace backwards?” -> “Trace to original trigger” [label=”yes”]; “Can trace backwards?” -> “Fix at symptom point” [label=”no - dead end”]; “Trace to original trigger” -> “BETTER: Also add defense-in-depth”; }[...]
This one is particularly fun because it then includes a Graphviz DOT graph) illustrating the process - it turns out Claude can interpret those as workflow instructions just fine, and Jesse has been wildly experimenting with them.
I vibe-coded up a quick URL-based DOT visualizer, here’s that one rendered:

There is so much to learn about putting these tools to work in the most effective way possible. Jesse is way ahead of the curve, so it’s absolutely worth spending some time exploring what he’s shared so far.
And if you’re worried about filling up your context with a bunch of extra stuff, here’s a reassuring note from Jesse:
The core of it is VERY token light. It pulls in one doc of fewer than 2k tokens. As it needs bits of the process, it runs a shell script to search for them. The long end to end chat for the planning and implementation process for that todo list app was 100k tokens.
It uses subagents to manage token-heavy stuff, including all the actual implementation.
(Jesse’s post also tipped me off about Claude’s /mnt/skills/public folder, see my notes here.)
Link 2025-10-10 simonw/claude-skills:
One of the tips I picked up from Jesse Vincent’s Claude Code Superpowers post (previously) was this:
Skills are what give your agents Superpowers.
The first time they really popped up on my radar was a few weeks ago when Anthropic rolled out improved Office document creation. When the feature rolled out, I went poking around a bit -- I asked Claude to tell me all about its new skills. And it was only too happy to dish.
In that transcript Jesse asks how the skill system works and Claude replies:
Looking at the skills system, here’s how it works:
Current Skills (in
/mnt/skills/public/):
docx - Word document handling
pdf - PDF processing and form filling
pptx - PowerPoint presentations
xlsx - Excel spreadsheets
This looks like it’s part of Claude’s brand new Code Interpreter feature! I wrote about that extensively last month, but I missed that there was a /mnt/skills/public/ folder full of fascinating implementation details.
So I fired up a fresh Claude instance (fun fact: Code Interpreter also works in the Claude iOS app now, which it didn’t when they first launched) and prompted:
Create a zip file of everything in your /mnt/skills folder
This worked, and gave me a .zip to download. You can run the prompt yourself here, though you’ll need to enable the new feature first.
I’ve pushed the contents of that zip to my new simonw/claude-skills GitHub repo.
So now you can see the prompts Anthropic wrote to enable the creation and manipulation of the following files in their Claude consumer applications:
In each case the prompts spell out detailed instructions for manipulating those file types using Python, using libraries that come pre-installed on Claude’s containers.
Skills are more than just prompts though: the repository also includes dozens of pre-written Python scripts for performing common operations.
pdf/scripts/fill_fillable_fields.py for example is a custom CLI tool that uses pypdf to find and then fill in a bunch of PDF form fields, specified as JSON, then render out the resulting combined PDF.
This is a really sophisticated set of tools for document manipulation, and I love that Anthropic have made those visible - presumably deliberately - to users of Claude who know how to ask for them.
Link 2025-10-11 An MVCC-like columnar table on S3 with constant-time deletes:
s3’s support for conditional writes (previously) makes it an interesting, scalable and often inexpensive platform for all kinds of database patterns.
Shayon Mukherjee presents an ingenious design for a Parquet-backed database in S3 which accepts concurrent writes, presents a single atomic view for readers and even supports reliable row deletion despite Parquet requiring a complete file rewrite in order to remove data.
The key to the design is a _latest_manifest JSON file at the top of the bucket, containing an integer version number. Clients use compare-and-swap to increment that version - only one client can succeed at this, so the incremented version they get back is guaranteed unique to them.
Having reserved a version number the client can write a unique manifest file for that version - manifest/v00000123.json - with a more complex data structure referencing the current versions of every persisted file, including the one they just uploaded.
Deleted rows are written to tombstone files as either a list of primary keys or a list of of ranges. Clients consult these when executing reads, filtering out deleted rows as part of resolving a query.
The pricing estimates are especially noteworthy:
For a workload ingesting 6 TB/day with 2 TB of deletes and 50K queries/day:
PUT requests: ~380K/day (≈4 req/s) = $1.88/day
GET requests: highly variable, depends on partitioning effectiveness
Best case (good time-based partitioning): ~100K-200K/day = $0.04-$0.08/day
Worst case (poor partitioning, scanning many files): ~2M/day = $0.80/day
~$3/day for ingesting 6TB of data is pretty fantastic!
Watch out for storage costs though - each new TB of data at $0.023/GB/month adds $23.55 to the ongoing monthly bill.
Note 2025-10-11 I’m beginning to suspect that a key skill in working effectively with coding agents is developing an intuition for when you don’t need to closely review every line of code they produce. This feels deeply uncomfortable!
Link 2025-10-11 Vibing a Non-Trivial Ghostty Feature:
Mitchell Hashimoto provides a comprehensive answer to the frequent demand for a detailed description of shipping a non-trivial production feature to an existing project using AI-assistance. In this case it’s a slick unobtrusive auto-update UI for his Ghostty terminal emulator, written in Swift.
Mitchell shares full transcripts of the 16 coding sessions he carried out using Amp Code across 2 days and around 8 hours of computer time, at a token cost of $15.98.
Amp has the nicest shared transcript feature of any of the coding agent tools, as seen in this example. I’d love to see Claude Code and Codex CLI and Gemini CLI and friends imitate this.
There are plenty of useful tips in here. I like this note about the importance of a cleanup step:
The cleanup step is really important. To cleanup effectively you have to have a pretty good understanding of the code, so this forces me to not blindly accept AI-written code. Subsequently, better organized and documented code helps future agentic sessions perform better.
I sometimes tongue-in-cheek refer to this as the “anti-slop session”.
And this on how sometimes you can write manual code in a way that puts the agent the right track:
I spent some time manually restructured the view model. This involved switching to a tagged union rather than the struct with a bunch of optionals. I renamed some types, moved stuff around.
I knew from experience that this small bit of manual work in the middle would set the agents up for success in future sessions for both the frontend and backend. After completing it, I continued with a marathon set of cleanup sessions.
Here’s one of those refactoring prompts:
Turn each @macos/Sources/Features/Update/UpdatePopoverView.swift case into a dedicated fileprivate Swift view that takes the typed value as its parameter so that we can remove the guards.
Mitchell advises ending every session with a prompt like this one, asking the agent about any obvious omissions:
Are there any other improvements you can see to be made with the @macos/Sources/Features/Update feature? Don’t write any code. Consult the oracle. Consider parts of the code that can also get more unit tests added.
(”Consult the oracle” is an Amp-specific pattern for running a task through a more expensive, more capable model.)
Is this all worthwhile? Mitchell thinks so:
Many people on the internet argue whether AI enables you to work faster or not. In this case, I think I shipped this faster than I would have if I had done it all myself, in particular because iterating on minor SwiftUI styling is so tedious and time consuming for me personally and AI does it so well.
I think the faster/slower argument for me personally is missing the thing I like the most: the AI can work for me while I step away to do other things.
Here’s the resulting PR, which touches 21 files.
Note 2025-10-11
Claude Code includes the ability to run sub-agents, where a separate agent loop with a fresh token context is dispatched to achieve a goal and report back when it’s done. I wrote a bit about how these work in June when I traced Claude Code’s activity by intercepting its API calls.
I recently learned that you can deliberately trigger Claude Code to use sub-agents just by telling it to do so!
Here’s an example. I ran this using Claude Code against a fresh checkout of simonw/datasette (commit ec38ad37689f3c14d307770977a17aed5efc5cb9), with no additional custom instructions:
Write markdown documentation for the context passed to each of the templates in this project. Use sub-agents.
Here’s a snippet of the output:
⏺ I’ll help you write markdown documentation for the context passed to each template in this project. Let me start by exploring the codebase to understand the template structure and then use sub-agents to document them comprehensively.
⏺ Search(pattern: “**/*.html”) ⎿ Found 47 files (ctrl+o to expand) ⏺ Search(pattern: “render.*template|render_template”) ⎿ Found 16 files (ctrl+o to expand)[...]
⏺ Now let me launch sub-agents to analyze different template contexts in parallel:
⏺ Task(Document index template context) ⎿ Done (12 tool uses · 86.4k tokens · 1m 13s) ⏺ Task(Document database template context) ⎿ Done (15 tool uses · 55.4k tokens · 1m 41s) ⏺ Task(Document table template context) ⎿ Done (14 tool uses · 85.2k tokens · 1m 44s) ⏺ Task(Document query/row template contexts) ⎿ Done (17 tool uses · 78.7k tokens · 1m 55s) ⏺ Task(Document special template contexts) ⎿ Done (26 tool uses · 116.1k tokens · 1m 50s)
It churned away for a couple of minutes (those sub-agents execute in parallel, another benefit of this pattern) and made me this template_contexts.md markdown file. It’s very comprehensive.
Link 2025-10-13 nanochat:
Really interesting new project from Andrej Karpathy, described at length in this discussion post.
It provides a full ChatGPT-style LLM, including training, inference and a web Ui, that can be trained for as little as $100:
This repo is a full-stack implementation of an LLM like ChatGPT in a single, clean, minimal, hackable, dependency-lite codebase.
It’s around 8,000 lines of code, mostly Python (using PyTorch) plus a little bit of Rust for training the tokenizer.
Andrej suggests renting a 8XH100 NVIDA node for around $24/ hour to train the model. 4 hours (~$100) is enough to get a model that can hold a conversation - almost coherent example here. Run it for 12 hours and you get something that slightly outperforms GPT-2. I’m looking forward to hearing results from longer training runs!
The resulting model is ~561M parameters, so it should run on almost anything. I’ve run a 4B model on my iPhone, 561M should easily fit on even an inexpensive Raspberry Pi.
The model defaults to training on ~24GB from karpathy/fineweb-edu-100b-shuffle derived from FineWeb-Edu, and then midtrains on 568K examples from SmolTalk (460K), MMLU auxiliary train (100K), and GSM8K (8K), followed by supervised finetuning on 21.4K examples from ARC-Easy (2.3K), ARC-Challenge (1.1K), GSM8K (8K), and SmolTalk (10K).
Here’s the code for the web server, which is fronted by this pleasantly succinct vanilla JavaScript HTML+JavaScript frontend.
Update: Sam Dobson pushed a build of the model to sdobson/nanochat on Hugging Face. It’s designed to run on CUDA but I pointed Claude Code at a checkout and had it hack around until it figured out how to run it on CPU on macOS, which eventually resulted in this script which I’ve published as a Gist. You should be able to try out the model using uv like this:
cd /tmp
git clone https://huggingface.co/sdobson/nanochat
uv run https://gist.githubusercontent.com/simonw/912623bf00d6c13cc0211508969a100a/raw/80f79c6a6f1e1b5d4485368ef3ddafa5ce853131/generate_cpu.py \
--model-dir /tmp/nanochat \
--prompt “Tell me about dogs.”I got this (truncated because it ran out of tokens):
I’m delighted to share my passion for dogs with you. As a veterinary doctor, I’ve had the privilege of helping many pet owners care for their furry friends. There’s something special about training, about being a part of their lives, and about seeing their faces light up when they see their favorite treats or toys.
I’ve had the chance to work with over 1,000 dogs, and I must say, it’s a rewarding experience. The bond between owner and pet
Link 2025-10-14 Just Talk To It - the no-bs Way of Agentic Engineering:
Peter Steinberger’s long, detailed description of his current process for using Codex CLI and GPT-5 Codex. This is information dense and full of actionable tips, plus plenty of strong opinions about the differences between Claude 4.5 an GPT-5:
While Claude reacts well to 🚨 SCREAMING ALL-CAPS 🚨 commands that threaten it that it will imply ultimate failure and 100 kittens will die if it runs command X, that freaks out GPT-5. (Rightfully so). So drop all of that and just use words like a human.
Peter is a heavy user of parallel agents:
I’ve completely moved to
codexcli as daily driver. I run between 3-8 in parallel in a 3x3 terminal grid, most of them in the same folder, some experiments go in separate folders. I experimented with worktrees, PRs but always revert back to this setup as it gets stuff done the fastest.
He shares my preference for CLI utilities over MCPs:
I can just refer to a cli by name. I don’t need any explanation in my agents file. The agent will try $randomcrap on the first call, the cli will present the help menu, context now has full info how this works and from now on we good. I don’t have to pay a price for any tools, unlike MCPs which are a constant cost and garbage in my context. Use GitHub’s MCP and see 23k tokens gone. Heck, they did make it better because it was almost 50.000 tokens when it first launched. Or use the
ghcli which has basically the same feature set, models already know how to use it, and pay zero context tax.
It’s worth reading the section on why he abandoned spec driven development in full.
Link 2025-10-15 A modern approach to preventing CSRF in Go:
Alex Edwards writes about the new http.CrossOriginProtection middleware that was added to the Go standard library in version 1.25 in August and asks:
Have we finally reached the point where CSRF attacks can be prevented without relying on a token-based check (like double-submit cookies)?
It looks like the answer might be yes, which is extremely exciting. I’ve been tracking CSRF since I first learned about it 20 years ago in May 2005 and a cleaner solution than those janky hidden form fields would be very welcome.
The code for the new Go middleware lives in src/net/http/csrf.go. It works using the Sec-Fetch-Site HTTP header, which Can I Use shows as having 94.18% global availability - the holdouts are mainly IE11, iOS versions prior to iOS 17 (which came out in 2023 but can be installed on any phone released since 2017) and some other ancient browser versions.
If Sec-Fetch-Site is same-origin or none then the page submitting the form was either on the same origin or was navigated to directly by the user - in both cases safe from CSRF. If it’s cross-site or same-site (tools.simonwillison.net and til.simonwillison.net are considered same-site but not same-origin) the submission is denied.
If that header isn’t available the middleware falls back on comparing other headers: Origin - a value like
https://simonwillison.net
- with Host, a value like simonwillison.net. This should cover the tiny fraction of browsers that don’t have the new header, though it’s not clear to me if there are any weird edge-cases beyond that.
Note that this fallback comparison can’t take the scheme into account since Host doesn’t list that, so administrators are encouraged to use HSTS to protect against HTTP to HTTPS cross-origin requests.
On Lobste.rs I questioned if this would work for localhost, since that normally isn’t served using HTTPS. Firefox security engineer Frederik Braun reassured me that *.localhost is treated as a Secure Context, so gets the Sec-Fetch-Site header despite not being served via HTTPS.
Update: Also relevant is Filippo Valsorda’s article in CSRF which includes detailed research conducted as part of building the new Go middleware, plus this related Bluesky conversation about that research from six months ago.
Excellent hands-on review Simon! Your point about the ecosytem being in early days is spot-on. The hardware capabilities are clearly impressive, but the real value will come from better documentation and tooling to help developers actually utilize the GB200's capabilities without needing to be CUDA experts. It's interesting how Nvidia is positioning this as a workstation rather than a server - that changes the target audience and use cases significantly.
how does performance compare to the M3/4 Pro/Max chips?