
Claude's new Code Interpreter
Plus: Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide

In this newsletter:
My review of Claude's new Code Interpreter, released under a very confusing name
Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide
Load Llama-3.2 WebGPU in your browser from a local folder (by Codex CLI)
Google’s new AI mode is actually really good! Totally different from AI overviews
Geoffrey Huntley’s vibe-coded programming language and compiler
My review of Claude's new Code Interpreter, released under a very confusing name - 2025-09-09
Today on the Anthropic blog: Claude can now create and edit files:
Claude can now create and edit Excel spreadsheets, documents, PowerPoint slide decks, and PDFs directly in Claude.ai and the desktop app. [...]
File creation is now available as a preview for Max, Team, and Enterprise plan users. Pro users will get access in the coming weeks.
Then right at the very end of their post:
This feature gives Claude internet access to create and analyze files, which may put your data at risk. Monitor chats closely when using this feature. Learn more.
And tucked away half way down their Create and edit files with Claude help article:
With this feature, Claude can also do more advanced data analysis and data science work. Claude can create Python scripts for data analysis. Claude can create data visualizations in image files like PNG. You can also upload CSV, TSV, and other files for data analysis and visualization.
Talk about burying the lede... this is their version of ChatGPT Code Interpreter, my all-time favorite feature of ChatGPT!
Claude can now write and execute custom Python (and Node.js) code in a server-side sandbox and use it to process and analyze data.
In a particularly egregious example of AI companies being terrible at naming features, the official name for this one really does appear to be Upgraded file creation and analysis. Sigh.
This is quite a confusing release, because Claude already had a variant of this feature, released in October 2024 with the weak but more sensible name Analysis tool. Here are my notes from when that came out. That tool worked by generating and executing JavaScript in the user's own browser.
The new tool works entirely differently. It's much closer in implementation to OpenAI's Code Interpreter: Claude now has access to a server-side container environment in which it can run shell commands and execute Python and Node.js code to manipulate data and both read and generate files.
Switching it on in settings/features
I have a Pro Plan but found the setting to enable it on the claude.ai/settings/features. It's possible my account was granted early access without me realizing, since the Pro plan isn't supposed to have it yet:

Interestingly, toggling on the "Upgraded file creation and analysis" option toggles off the "Analysis tool" option, and vice versa. You can't have both at the same time.
I guess this is to help reduce confusion? It surprised me though as Claude can sometimes use the existing analysis tool to help it in the creation of artifacts, as I noted here when I wrote about the Claudeception feature they added in June.
Exploring the environment
I started by using the tool to explore the tool. Here's my first transcript where I simply prompted the following to see what it could figure out about itself:
Tell me everything you can about your shell and Python environments
Here's part of the output:

And the key details it returned, each of which I've verified as true by checking the displayed output of the relevant commands:
OS: Ubuntu 24.04.2 LTS (Noble) running on Linux kernel 4.4.0-
Architecture: x86_64
Shell: GNU Bash 5.2.21(1)-release
Current User: root (with access to /home/claude directory)
Working Directory: Currently in root (/), but /home/claude is the main workspace
Python Version: Python 3.12.3
Python Executable: /usr/bin/python3
Package Manager: pip 24.0
Python Path: Standard system locations including:
/usr/lib/python3.12 (standard library)
/usr/local/lib/python3.12/dist-packages (local packages)
Disk Space: 4.9GB total, with 4.6GB available
Memory: 9.0GB RAM available, minimal usage currently
Node.js: v18.19.1 available
npm: Configured with global packages in
/home/claude/.npm-global
So we have an Ubuntu 24.04.2 container with 9GB of RAM, ~5GB of disk, Python 3.12.3, and Node.js v18.19.1.
How about network access? I tried the following:
Can you access the Internet? Can you run curl? How about using Python http to fetch https://latest.datasette.io/fixtures.json ?
Again, you can see the detailed output in the transcript. Claude tried https://latest.datasette.io/fixtures.json and then https://httpbin.org/json and got a 403 forbidden error for both, then
https://google.com
and got this curious result:
curl -s -I https://google.comOutput:
HTTP/1.1 200 OK
date: Tue, 09 Sep 2025 16:02:17 GMT
server: envoy
HTTP/2 403
content-length: 13
content-type: text/plain
date: Tue, 09 Sep 2025 16:02:17 GMTClaude did note that it can still use the web_fetch and web_search containers independently of that container environment, so it should be able to fetch web content using tools running outside of the container and then write it to a file there.
On a hunch I tried this:
Run pip install sqlite-utils
... and it worked! Claude can pip install additional packages from PyPI.
A little more poking around revealed the following relevant environment variables:
HTTPS_PROXY=http://21.0.0.167:15001
no_proxy=localhost,127.0.0.1,169.254.169.254,metadata.google.internal,*.svc.cluster.local,*.local,*.googleapis.com,*.google.com
NO_PROXY=localhost,127.0.0.1,169.254.169.254,metadata.google.internal,*.svc.cluster.local,*.local,*.googleapis.com,*.google.com
https_proxy=http://21.0.0.167:15001
http_proxy=http://21.0.0.167:15001So based on an earlier HTTP header there's an Envoy proxy running at an accessible port which apparently implements a strict allowlist.
I later noticed that the help page includes a full description of what's on that allowlist:
Anthropic Services (Explicit)
api.anthropic.com, statsig.anthropic.com
Version Control
github.com
Package Managers - JavaScript/Node
NPM: registry.npmjs.org, npmjs.com, npmjs.org
Yarn: yarnpkg.com, registry.yarnpkg.comPackage Managers - Python
pypi.org, files.pythonhosted.org, pythonhosted.org
So it looks like we have a very similar system to ChatGPT Code Interpreter. The key differences are that Claude's system can install additional Python packages and has Node.js pre-installed.
One important limitation from the docs:
The maximum file size is 30MB per file for both uploads and downloads.
The ChatGPT limit here is 512MB. I've often uploaded 100MB+ SQLite database files to ChatGPT, so I'm a little disappointed by this lower limit for Claude.
Starting with something easy
I grabbed a copy of the SQLite database behind my TILs website (21.9MB from here) and uploaded it to Claude, then prompted:
Use your Python environment to explore this SQLite database and generate a PDF file containing a join diagram of all the tables
Here's that conversation. It did an OK job, producing both the PDF I asked for and a PNG equivalent which looks like this (since created files are not available in shared chats):

This isn't an ideal result - those join lines are difficult to follow - but I'm confident I could get from here to something I liked with only a little more prompting. The important thing is that the system clearly works, and can analyze data in uploaded SQLite files and use them to produce images and PDFs.
Something much harder: recreating the AI adoption chart
Thankfully I have a fresh example of a really challenging ChatGPT Code Interpreter task from just last night, which I described in great detail in Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide.
Short version: I took this chart from Apollo Global and asked ChatGPT to recreate it based on a screenshot and an uploaded XLSX file.

This time I skipped the bit where I had ChatGPT hunt down the original data and jumped straight to the "recreate this chart" step. I used the exact same prompt as I provided to ChatGPT:
Use this data to recreate this chart using python
And uploaded the same two files - this XLSX file and the screenshot of the original chart.
{kind=link}

Claude wrote and ran a bunch of Python code and produced this:

That's not a bad first attempt - we'll sort out the jagged lines in a moment. With ChatGPT I later told it to plot a six-survey rolling average (since that's what Apollo had done with theirs), so I ran the exact same prompt against Claude:
Plot it as a six survey rolling average

So I told Claude:
Make those lines less jagged
This did not do what I wanted:

So I gave it a bit of a hint:
No not like that, I wanted the lines to be a smooth curve like in the original screenshot - you shouldn't have to use scipy for this or manipulate the data, I'm sure matplotlib can do this already
A little bit of sycophancy:
You're absolutely right! Matplotlib has built-in curve smoothing. I was overcomplicating it. Let me create a version that uses matplotlib's natural curve smoothing capabilities. [...]
This time it used the antialiased=True and solid_capstyle='round' options in matplotlib, which again wasn't what I was after. I tried one more thing:
I did not mean smooth the rendering of the lines. I meant that I wanted curved and not straight lines between points.
(Normally if I have to argue this much with a model I'll start a fresh session and try a different prompting strategy from the start.)
But this did give me what I was looking for:

Oddly enough my ChatGPT chart suffered from that same overlapping title glitch, so I gave Claude the same prompt I had given ChatGPT:
fix the chart title, it looks like this:(with a screenshot)

We got there in the end! I've shared the full transcript of the chat, although frustratingly the images and some of the code may not be visible. I created this Gist with copies of the files that it let me download.
Prompt injection risks
ChatGPT Code Interpreter has no access to the internet at all, which limits how much damage an attacker can do if they manage to sneak their own malicious instructions into the model's context.
Since Claude Code Interpreter (I'm not going to be calling it "Upgraded file creation and analysis"!) has a limited form of internet access, we need to worry about lethal trifecta and other prompt injection attacks.
The help article actually covers this in some detail:
It is possible for a bad actor to inconspicuously add instructions via external files or websites that trick Claude into:
Downloading and running untrusted code in the sandbox environment for malicious purposes.
Reading sensitive data from a claude.ai connected knowledge source (e.g., Remote MCP, projects) and using the sandbox environment to make an external network request to leak the data.
This means Claude can be tricked into sending information from its context (e.g., prompts, projects, data via MCP, Google integrations) to malicious third parties. To mitigate these risks, we recommend you monitor Claude while using the feature and stop it if you see it using or accessing data unexpectedly.
"We recommend you monitor Claude while using the feature" smells me to me like unfairly outsourcing the problem to Anthropic's users, but I'm not sure what more they can do!
It's interesting that they still describe the external communication risk even though they've locked down a lot of network access. My best guess is that they know that allowlisting github.com opens an enormous array of potential exfiltration vectors.
Anthropic also note:
We have performed red-teaming and security testing on the feature. We have a continuous process for ongoing security testing and red-teaming of this feature.
I plan to be cautious using this feature with any data that I very much don't want to be leaked to a third party, if there's even the slightest chance that a malicious instructions might sneak its way in.
My verdict on Claude Code Interpreter so far
I'm generally very excited about this. Code Interpreter has been my most-valued LLM feature since it launched in early 2023, and the Claude version includes some upgrades on the original - package installation, Node.js support - that I expect will be very useful.
I don't particularly mark it down for taking a little more prompting to recreate the Apollo chart than ChatGPT did. For one thing I was using Claude Sonnet 4 - I expect Claude Opus 4.1 would have done better. I also have a much stronger intuition for Code Interpreter prompts that work with GPT-5.
I don't think my chart recreation exercise here should be taken as showing any meaningful differences between the two.
AI labs find explaining this feature incredibly difficult
I find it fascinating how difficult the AI labs find describing this feature to people! OpenAI went from "Code Interpreter" to "Advanced Data Analysis" and maybe back again? It's hard to even find their official landing page for that feature now. (I got GPT-5 to look for it and it hunted for 37 seconds and settled on the help page for Data analysis with ChatGPT).
Anthropic already used the bad name "Analysis tool" for a different implementation, and now have the somehow-worse name "Upgraded file creation and analysis". Their launch announcement avoids even talking about code execution, focusing exclusively on the tool's ability to generate spreadsheets and PDFs!
I wonder if any of the AI labs will crack the code on how to name and explain this thing? I feel like it's still a very under-appreciated feature of LLMs, despite having been around for more than two years now.
Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide - 2025-09-09
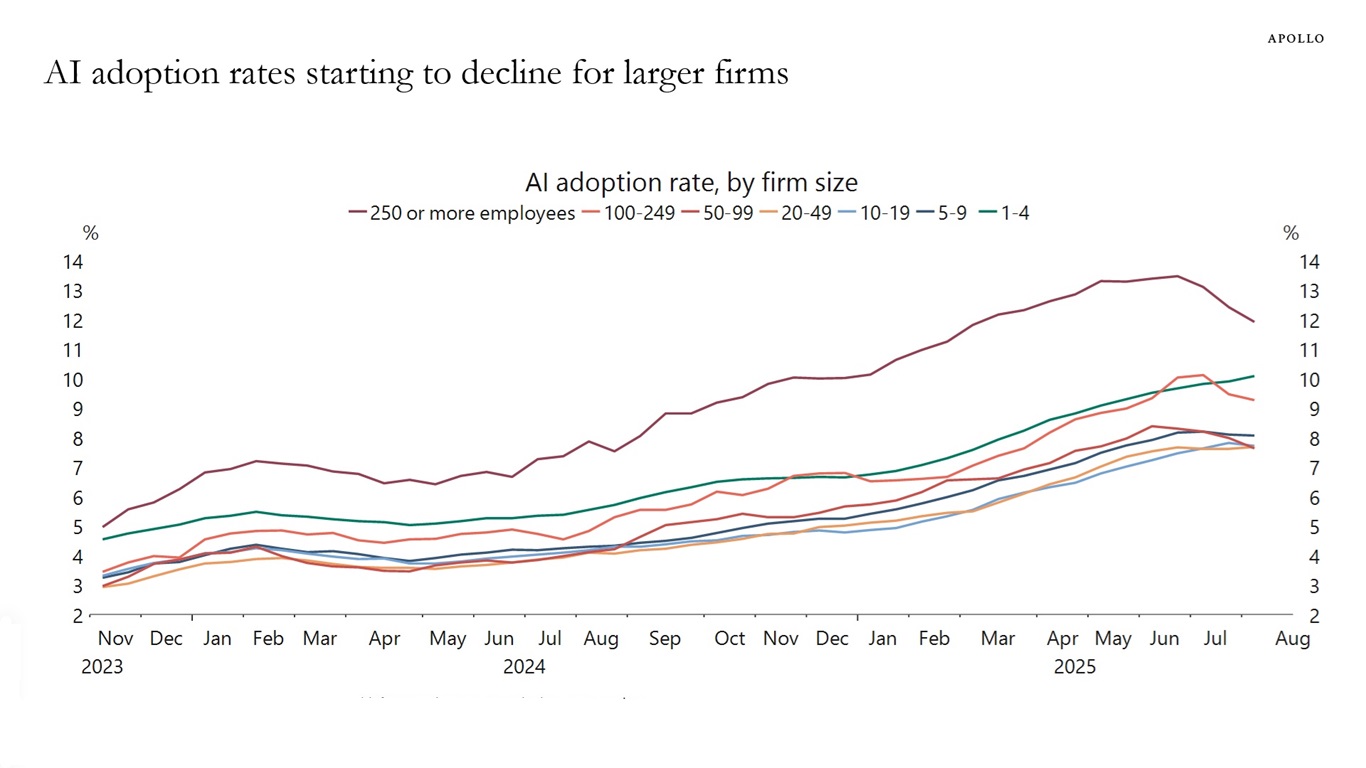
Apollo Global Management's "Chief Economist" Dr. Torsten Sløk released this interesting chart which appears to show a slowdown in AI adoption rates among large (>250 employees) companies:
Here's the full description that accompanied the chart:
The US Census Bureau conducts a biweekly survey of 1.2 million firms, and one question is whether a business has used AI tools such as machine learning, natural language processing, virtual agents or voice recognition to help produce goods or services in the past two weeks. Recent data by firm size shows that AI adoption has been declining among companies with more than 250 employees, see chart below.
(My first thought on seeing that chart is that I hope it represents the peak of inflated expectations leading into the trough of dissillusionment in the Gartner Hype Cycle (which Wikipedia calls "largely disputed, with studies pointing to it being inconsistently true at best"), since that means we might be reaching the end of the initial hype phase and heading towards the slope of enlightenment.)
Finding the US Census data with GPT-5 search
This is the first I'd heard of the US Census Bureau running a biweekly (that's once every two weeks) survey about AI!
I decided to track down the numbers and see if I could recreate the chart myself. And since GPT-5 is really good at search now I fed it the following prompt to see how well it could do:
> The US Census Bureau conducts a biweekly survey of 1.2 million firms, and one question is whether a business has used AI tools such as machine learning, natural language processing, virtual agents or voice recognition to help produce goods or services in the past two weeks. Recent data by firm size shows that AI adoption has been declining among companies with more than 250 employees, see chart below.
Find me that original data
It took 1m19s to find exactly what I needed:
Here’s the original U.S. Census Bureau source for that series:
BTOS “Employment size class” time series (XLSX) — biweekly shares of firms answering Yes to “In the last two weeks, did this business use Artificial Intelligence (AI) in producing goods or services?”, broken out by firm-size buckets (incl. 250+ employees). Coverage: Sep 11, 2023 → Aug 24, 2025. (Census.gov) [...]
That Census page was not at all obvious. Thankfully GPT-5 had tipped me off to the "Employment size class" file, this link here:

So I downloaded that file, and confirmed that it was indeed a spreadsheet containing the data I wanted (in among all sorts of other survey questions). Here's a 374KB XLSX copy of the file I downloaded.
Recreating the chart with GPT-5 code interpreter
So what should I do with it now? I decided to see if GPT-5 could turn the spreadsheet back into that original chart, using Python running in its code interpreter tool.
So I uploaded the XLSX file back to ChatGPT, dropped in a screenshot of the Apollo chart and prompted:
Use this data to recreate this chart using python

I thought this was a pretty tall order, but it's always worth throwing big challenges at an LLM to learn from how well it does.
It really worked hard on this. I didn't time it exactly but it spent at least 7 minutes "reasoning" across 5 different thinking blocks, interspersed with over a dozen Python analysis sessions. It used pandas and numpy to explore the uploaded spreadsheet and find the right figures, then tried several attempts at plotting with matplotlib.
As far as I can tell GPT-5 in ChatGPT can now feed charts it creates back into its own vision model, because it appeared to render a broken (empty) chart and then keep on trying to get it working.
It found a data dictionary in the last tab of the spreadsheet and used that to build a lookup table matching the letters A through G to the actual employee size buckets.
At the end of the process it spat out this chart:

At first glance I thought it had nailed it... but then I compared the chart more closely with the Apollo original and spotted some definite discrepancies. GPT-5's chart peaked at 14.5% but the highest value in Apollo's was more like 13.5%. The GPT-5 chart was spikier - and most interestingly it included a clear uptick in the last data point where Apollo's had trended downwards.
I decided it was time to look at the actual data. I opened up the spreadsheet in Numbers, found the AI question columns and manually reviewed them. They seemed to match the GPT-5 chart results - so why the difference to Apollo's?
Then I noticed a crucial detail in the Apollo chart that I had cropped out of my original screenshot!
Note: Data is six-survey moving average.
So I told ChatGPT:
Do the first question, plot it as a six survey rolling average
I asked for the first question because it turned out there were two that were relevant in the survey spreadsheet.
In the last two weeks, did this business use Artificial Intelligence (AI) in producing goods or services? (Examples of AI: machine learning, natural language processing, virtual agents, voice recognition, etc.)
During the next six months, do you think this business will be using Artificial Intelligence (AI) in producing goods or services? (Examples of AI: machine learning, natural language processing, virtual agents, voice recognition, etc.)
It churned away for a little longer, added this code to the script:
# Compute 6-survey rolling average (biweekly cadence → ~12 weeks)
rolled = wide.rolling(window=6, min_periods=6).mean()And popped out this chart (after I told it to fix the glitch in the title):

I think it's done it! This is a very solid match for the Apollo original, recreated using matplotlib and pandas from the same underlying source data from the US Census.
Here's the full Python code it wrote, which I think is quite readable (in as much as Pandas code can be):
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.ticker import PercentFormatter
path = "/mnt/data/Employment Size Class.xlsx"
resp = pd.read_excel(path, sheet_name="Response Estimates")
dates = pd.read_excel(path, sheet_name="Collection and Reference Dates")
is_current = resp["Question"].astype(str).str.strip().str.startswith("In the last two weeks")
ai_yes = resp[is_current & resp["Answer"].astype(str).str.strip().str.lower().eq("yes")].copy()
code_to_bucket = {"A":"1-4","B":"5-9","C":"10-19","D":"20-49","E":"50-99","F":"100-249","G":"250 or more employees"}
ai_yes["Bucket"] = ai_yes["Empsize"].map(code_to_bucket)
period_cols = [c for c in ai_yes.columns if str(c).isdigit() and len(str(c))==6]
long = ai_yes.melt(id_vars=["Bucket"], value_vars=period_cols, var_name="Smpdt", value_name="value")
dates["Smpdt"] = dates["Smpdt"].astype(str)
long["Smpdt"] = long["Smpdt"].astype(str)
merged = long.merge(dates[["Smpdt","Ref End"]], on="Smpdt", how="left")
merged["date"] = pd.to_datetime(merged["Ref End"], errors="coerce")
merged["value"] = pd.to_numeric(long["value"].astype(str).str.replace("%","",regex=False).str.strip(), errors="coerce")
order = ["250 or more employees","100-249","50-99","20-49","10-19","5-9","1-4"]
wide = merged.pivot_table(index="date", columns="Bucket", values="value", aggfunc="mean").sort_index()
wide = wide[[c for c in order if c in wide.columns]]
rolled = wide.rolling(window=6, min_periods=6).mean()
start, end = pd.Timestamp("2023-11-01"), pd.Timestamp("2025-08-31")
rolled_win = rolled.loc[(rolled.index >= start) & (rolled.index <= end)]
fig, ax = plt.subplots(figsize=(12, 6))
for col in order:
if col in rolled_win.columns:
ax.plot(rolled_win.index, rolled_win[col], label=col, linewidth=2)
ax.set_title("AI adoption (last two weeks) — 6‑survey rolling average", pad=16)
ax.yaxis.set_major_formatter(PercentFormatter(100))
ax.set_ylabel("%")
ax.set_xlabel("")
ax.grid(True, alpha=0.25, linestyle="--")
ax.legend(title=None, loc="upper left", ncols=2, frameon=False)
plt.tight_layout()
png_path = "/mnt/data/ai_adoption_rolling6_by_firm_size.png"
svg_path = "/mnt/data/ai_adoption_rolling6_by_firm_size.svg"
plt.savefig(png_path, dpi=200, bbox_inches="tight")
plt.savefig(svg_path, bbox_inches="tight")I like how it generated an SVG version of the chart without me even asking for it.
{kind=link}
You can access the ChatGPT transcript to see full details of everything it did.
Rendering that chart client-side using Pyodide
I had one more challenge to try out. Could I render that same chart entirely in the browser using Pyodide, which can execute both Pandas and Matplotlib?
I fired up a new ChatGPT GPT-5 session and prompted:
Build a canvas that loads Pyodide and uses it to render an example bar chart with pandas and matplotlib and then displays that on the page
My goal here was simply to see if I could get a proof of concept of a chart rendered, ideally using the Canvas feature of ChatGPT. Canvas is OpenAI's version of Claude Artifacts, which lets the model write and then execute HTML and JavaScript directly in the ChatGPT interface.
It worked! Here's the transcript and here's what it built me, exported to my tools.simonwillison.net GitHub Pages site (source code here).
\" showing blue bars for months Jan through Jun with values approximately: Jan(125), Feb(130), Mar(80), Apr(85), May(85), Jun(120). Y-axis labeled \"Streams\" ranges 0-120, X-axis labeled \"Month\".")
I've now proven to myself that I can render those Python charts directly in the browser. Next step: recreate the Apollo chart.
I knew it would need a way to load the spreadsheet that was CORS-enabled. I uploaded my copy to my /static/cors-allow/2025/... directory (configured in S3 to serve CORS headers), pasted in the finished plotting code from earlier and told ChatGPT:
Now update it to have less explanatory text and a less exciting design (black on white is fine) and run the equivalent of this:(... pasted in Python code from earlier ...)
Load the XLSX sheet from https://static.simonwillison.net/static/cors-allow/2025/Employment-Size-Class-Sep-2025.xlsx
It didn't quite work - I got an error about openpyxl which I manually researched the fix for and prompted:
Use await micropip.install("openpyxl") to install openpyxl - instead of using loadPackage
I had to paste in another error message:
zipfile.BadZipFile: File is not a zip file
Then one about a SyntaxError: unmatched ')' and a TypeError: Legend.__init__() got an unexpected keyword argument 'ncols' - copying and pasting error messages remains a frustrating but necessary part of the vibe-coding loop.
... but with those fixes in place, the resulting code worked! Visit tools.simonwillison.net/ai-adoption to see the final result:

Here's the code for that page, 170 lines all-in of HTML, CSS, JavaScript and Python.
What I've learned from this
This was another of those curiosity-inspired investigations that turned into a whole set of useful lessons.
GPT-5 is great at tracking down US Census data, no matter how difficult their site is to understand if you don't work with their data often
It can do a very good job of turning data + a screenshot of a chart into a recreation of that chart using code interpreter, Pandas and matplotlib
Running Python + matplotlib in a browser via Pyodide is very easy and only takes a few dozen lines of code
Fetching an XLSX sheet into Pyodide is only a small extra step using
pyfetchandopenpyxl:
import micropip
await micropip.install("openpyxl")
from pyodide.http import pyfetch
resp_fetch = await pyfetch(URL)
wb_bytes = await resp_fetch.bytes()
xf = pd.ExcelFile(io.BytesIO(wb_bytes), engine='openpyxl')Another new-to-me pattern: you can render an image to the DOM from Pyodide code like this:
from js import document
document.getElementById('plot').src = 'data:image/png;base64,' + img_b64I will most definitely be using these techniques again in future.
Update: Coincidentally Claude released their own upgraded equivalent to ChatGPT Code Interpreter later on the day that I published this story, so I ran the same chart recreation experiment against Claude Sonnet 4 to see how it compared.
Note 2025-09-07
When I wrote about how good ChatGPT with GPT-5 is at search yesterday I nearly added a note about how comparatively disappointing Google's efforts around this are.
I'm glad I left that out, because it turns out Google's new "AI mode" is genuinely really good! It feels very similar to GPT-5 search but returns results much faster.
www.google.com/ai (not available in the EU, as I found out this morning since I'm staying in France for a few days.)
Here's what I got for the following question:
Anthropic but lots of physical books and cut them up and scan them for training data. Do any other AI labs do the same thing?

I'll be honest: I hadn't spent much time with AI mode for a couple of reasons:
My expectations of "AI mode" were extremely low based on my terrible experience of "AI overviews"
The name "AI mode" is so generic!
Based on some initial experiments I'm impressed - Google finally seem to be taking full advantage of their search infrastructure for building out truly great AI-assisted search.
I do have one disappointment: AI mode will tell you that it's "running 5 searches" but it won't tell you what those searches are! Seeing the searches that were run is really important for me in evaluating the likely quality of the end results. I've had the same problem with Google's Gemini app in the past - the lack of transparency as to what it's doing really damages my trust.
Link 2025-09-07 The SIFT method:
The SIFT method is "an evaluation strategy developed by digital literacy expert, Mike Caulfield, to help determine whether online content can be trusted for credible or reliable sources of information."
This looks extremely useful as a framework for helping people more effectively consume information online (increasingly gathered with the help of LLMs).
Stop. "Be aware of your emotional response to the headline or information in the article" to protect against clickbait, and don't read further or share until you've applied the other three steps.
Investigate the Source. Apply lateral reading, checking what others say about the source rather than just trusting their "about" page.
Find Better Coverage. "Use lateral reading to see if you can find other sources corroborating the same information or disputing it" and consult trusted fact checkers if necessary.
Trace Claims, Quotes, and Media to their Original Context. Try to find the original report or referenced material to learn more and check it isn't being represented out of context.
This framework really resonates with me: it formally captures and improves on a bunch of informal techniques I've tried to apply in my own work.
quote 2025-09-07
I agree with the intellectual substance of virtually every common critique of AI. And it's very clear that turning those critiques into a competition about who can frame them in the most scathing way online has done zero to slow down adoption, even if much of that is due to default bundling.
At what point are folks going to try literally any other tactic than condescending rants? Does it matter that LLM apps are at the top of virtually every app store nearly every day because individual people are choosing to download them, and the criticism hasn't been effective in slowing that?
Link 2025-09-07 Is the LLM response wrong, or have you just failed to iterate it?:
More from Mike Caulfield (see also the SIFT method). He starts with a fantastic example of Google's AI mode usually correctly handling a common piece of misinformation but occasionally falling for it (the curse of non-deterministic systems), then shows an example if what he calls a "sorting prompt" as a follow-up:
What is the evidence for and against this being a real photo of Shirley Slade?
The response starts with a non-committal "there is compelling evidence for and against...", then by the end has firmly convinced itself that the photo is indeed a fake. It reads like a fact-checking variant of "think step by step".
Mike neatly describes a problem I've also observed recently where "hallucination" is frequently mis-applied as meaning any time a model makes a mistake:
The term hallucination has become nearly worthless in the LLM discourse. It initially described a very weird, mostly non-humanlike behavior where LLMs would make up things out of whole cloth that did not seem to exist as claims referenced any known source material or claims inferable from any known source material. Hallucinations as stuff made up out of nothing. Subsequently people began calling any error or imperfect summary a hallucination, rendering the term worthless.
In this example is the initial incorrect answers were not hallucinations: they correctly summarized online content that contained misinformation. The trick then is to encourage the model to look further, using "sorting prompts" like these:
Facts and misconceptions and hype about what I posted
What is the evidence for and against the claim I posted
Look at the most recent information on this issue, summarize how it shifts the analysis (if at all), and provide link to the latest info
I appreciated this closing footnote:
Should platforms have more features to nudge users to this sort of iteration? Yes. They should. Getting people to iterate investigation rather than argue with LLMs would be a good first step out of this mess that the chatbot model has created.
quote 2025-09-08
I recently spoke with the CTO of a popular AI note-taking app who told me something surprising: they spend twice as much on vector search as they do on OpenAI API calls. Think about that for a second. Running the retrieval layer costs them more than paying for the LLM itself.
James Luan, Engineering architect of Milvus
Link 2025-09-08 Load Llama-3.2 WebGPU in your browser from a local folder:
Inspired by a comment on Hacker News I decided to see if it was possible to modify the transformers.js-examples/tree/main/llama-3.2-webgpu Llama 3.2 chat demo (online here, I wrote about it last November) to add an option to open a local model file directly from a folder on disk, rather than waiting for it to download over the network.
I posed the problem to OpenAI's GPT-5-enabled Codex CLI like this:
git clone https://github.com/huggingface/transformers.js-examples
cd transformers.js-examples/llama-3.2-webgpu
codexThen this prompt:
Modify this application such that it offers the user a file browse button for selecting their own local copy of the model file instead of loading it over the network. Provide a "download model" option too.
Codex churned away for several minutes, even running commands like curl -sL https://raw.githubusercontent.com/huggingface/transformers.js/main/src/models.js | sed -n '1,200p' to inspect the source code of the underlying Transformers.js library.
After four prompts total (shown here) it built something which worked!
To try it out you'll need your own local copy of the Llama 3.2 ONNX model. You can get that (a ~1.2GB) download) like so:
git lfs install
git clone https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct-q4f16
Then visit my llama-3.2-webgpu page in Chrome or Firefox Nightly (since WebGPU is required), click "Browse folder", select that folder you just cloned, agree to the "Upload" confirmation (confusing since nothing is uploaded from your browser, the model file is opened locally on your machine) and click "Load local model".
Here's an animated demo (recorded in real-time, I didn't speed this up):

I pushed a branch with those changes here. The next step would be to modify this to support other models in addition to the Llama 3.2 demo, but I'm pleased to have got to this proof of concept with so little work beyond throwing some prompts at Codex to see if it could figure it out.
According to the Codex /status command this used 169,818 input tokens, 17,112 output tokens and 1,176,320 cached input tokens. At current GPT-5 token pricing ($1.25/million input, $0.125/million cached input, $10/million output) that would cost 53.942 cents, but Codex CLI hooks into my existing $20/month ChatGPT Plus plan so this was bundled into that.
quote 2025-09-08
Having worked inside AWS I can tell you one big reason [that they don't describe their internals] is the attitude/fear that anything we put in out public docs may end up getting relied on by customers. If customers rely on the implementation to work in a specific way, then changing that detail requires a LOT more work to prevent breaking customer's workloads. If it is even possible at that point.
TheSoftwareGuy, comment on Hacker News
Link 2025-09-09 Anthropic status: Model output quality:
Anthropic previously reported model serving bugs that affected Claude Opus 4 and 4.1 for 56.5 hours. They've now fixed additional bugs affecting "a small percentage" of Sonnet 4 requests for almost a month, plus a less long-lived Haiku 3.5 issue:
Resolved issue 1 - A small percentage of Claude Sonnet 4 requests experienced degraded output quality due to a bug from Aug 5-Sep 4, with the impact increasing from Aug 29-Sep 4. A fix has been rolled out and this incident has been resolved.
Resolved issue 2 - A separate bug affected output quality for some Claude Haiku 3.5 and Claude Sonnet 4 requests from Aug 26-Sep 5. A fix has been rolled out and this incident has been resolved.
They directly address accusations that these stem from deliberate attempts to save money on serving models:
Importantly, we never intentionally degrade model quality as a result of demand or other factors, and the issues mentioned above stem from unrelated bugs.
The timing of these issues is really unfortunate, corresponding with the rollout of GPT-5 which I see as the non-Anthropic model to feel truly competitive with Claude for writing code since their release of Claude 3.5 back in June last year.
Link 2025-09-09 I ran Claude in a loop for three months, and it created a genz programming language called cursed:
Geoffrey Huntley vibe-coded an entirely new programming language using Claude:
The programming language is called "cursed". It's cursed in its lexical structure, it's cursed in how it was built, it's cursed that this is possible, it's cursed in how cheap this was, and it's cursed through how many times I've sworn at Claude.
Geoffrey's initial prompt:
Hey, can you make me a programming language like Golang but all the lexical keywords are swapped so they're Gen Z slang?
Then he pushed it to keep on iterating over a three month period.
Here's Hello World:
vibe main
yeet "vibez"
slay main() {
vibez.spill("Hello, World!")
}And here's binary search, part of 17+ LeetCode problems that run as part of the test suite:
slay binary_search(nums normie[], target normie) normie {
sus left normie = 0
sus right normie = len(nums) - 1
bestie (left <= right) {
sus mid normie = left + (right - left) / 2
ready (nums[mid] == target) {
damn mid
}
ready (nums[mid] < target) {
left = mid + 1
} otherwise {
right = mid - 1
}
}
damn -1
}This is a substantial project. The repository currently has 1,198 commits. It has both an interpreter mode and a compiler mode, and can compile programs to native binaries (via LLVM) for macOS, Linux and Windows.
It looks like it was mostly built using Claude running via Sourcegraph's Amp, which produces detailed commit messages. The commits include links to archived Amp sessions but sadly those don't appear to be publicly visible.
The first version was written in C, then Geoffrey had Claude port it to Rust and then Zig. His cost estimate:
Technically it costs about 5k usd to build your own compiler now because cursed was implemented first in c, then rust, now zig. So yeah, it’s not one compiler it’s three editions of it. For a total of $14k USD.
Link 2025-09-09 The 2025 PSF Board Election is Open!:
The Python Software Foundation's annual board member election is taking place right now, with votes (from previously affirmed voting members) accepted from September 2nd, 2:00 pm UTC through Tuesday, September 16th, 2:00 pm UTC.
I've served on the board since 2022 and I'm running for a second term. Here's the opening section of my nomination statement.
Hi, I'm Simon Willison. I've been a board member of the Python Software Foundation since 2022 and I'm running for re-election in 2025.
Last year I wrote a detailed article about Things I’ve learned serving on the board of the Python Software Foundation. I hope to continue learning and sharing what I've learned for a second three-year term.
One of my goals for a second term is to help deepen the relationship between the AI research world and the Python Software Foundation. There is an enormous amount of value being created in the AI space using Python and I would like to see more of that value flow back into the rest of the Python ecosystem.
I see the Python Package Index (PyPI) as one of the most impactful projects of the Python Software Foundation and plan to continue to advocate for further investment in the PyPI team and infrastructure.
As a California resident I'm excited to see PyCon return to the West Coast, and I'm looking forward to getting involved in helping make PyCon 2026 and 2027 in Long Beach, California as successful as possible.
I'm delighted to have been endorsed this year by Al Sweigart, Loren Crary and Christopher Neugebauer. If you are a voting member I hope I have earned your vote this year.
You can watch video introductions from several of the other nominees in this six minute YouTube video and this playlist.
Is this available through the API?
some very cool stuff